What is the Model Explorer?
Support for large models
Decision making commonly requires access to massive amounts of information on which to base the decision making process. As a result, professional decision support systems are usually very complex programs with hundreds of (indexed) identifiers to store all the data that are relevant to the decision making process. In such systems, finding your way through the source code is therefore a cumbersome task. To support you in this process, AIMMS makes all model declarations and procedures available in a special tool called the Model Explorer.
Structured model representation
The AIMMS Model Explorer provides you with a simple graphical model representation. All relevant information is stored in the form of a model tree, an example of which is shown in Fig. 10.
As you can see in this example, AIMMS does not prescribe a fixed declaration order, but leaves it up to you to structure all the information in the model in any way that you find useful.
Different node types
As illustrated in Fig. 10, the model tree lets you store information of different types, such as identifier declarations, procedures, functions, and model sections. Each piece of information is stored as a separate node in the model tree, where each node has its own type-dependent icon. In this section, the main node types in the model tree will be briefly introduced. In subsequent chapters, the details of all model-related node types such as identifiers, procedures and functions will be discussed in further detail.
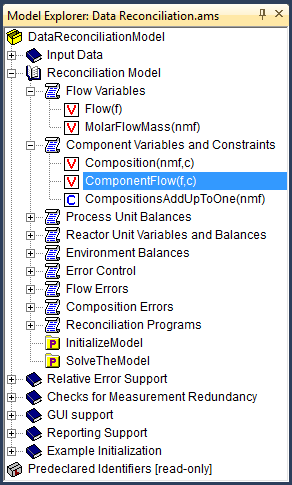
Fig. 10 Example of a model tree
Structuring nodes
There are three basic node types available for structuring the model tree. You can branch further from these nodes to provide more depth to the model tree. These basic types are:
The main model node which forms the root of the model tree. The main model is represented by a box icon
 which opens when
the model tree is expanded, and can contain book sections,
declaration sections, procedures and functions.
which opens when
the model tree is expanded, and can contain book sections,
declaration sections, procedures and functions.Book section nodes are used to subdivide a model into logical parts with clear and descriptive names. Book sections are represented by a book icon
 which opens when the section is expanded. A
book section can contain other book sections, declaration sections,
procedures and functions.
which opens when the section is expanded. A
book section can contain other book sections, declaration sections,
procedures and functions.Declaration section nodes are used to group identifier declarations of your model. Declaration sections are represented by a scroll icon
 , and can only contain identifier declaration nodes.
, and can only contain identifier declaration nodes.
Advantages
The structuring nodes allow you to subdivide the information in your model into a logical framework of sections with clear and descriptive names. This is one of the major advantages of the AIMMS model tree over a straightforward text model representation, as imposing such a logical subdivision makes it much easier to locate the relevant information when needed later on. This helps to reduce the maintenance cost of AIMMS applications drastically.
Module and library nodes
In addition to the basic structuring nodes discussed above, AIMMS supports two additional structuring node types, which are aimed at re-use of parts of a model and working on a single AIMMS project with multiple developers.
The module node offers the same functionality as a book section, but stores the identifiers it defines in a separate namespace. This allows a module to be included in multiple models without the risk of name clashes. Module nodes are represented by the icon
 .
.The library module node is the source module associated with a library project (see Library projects and the library manager). Library modules can only be added to or deleted from a model through the Library Manager, and are always displayed as a separate root in the model tree. Library module nodes are represented by the icon
 .
.
Modules, library modules and the difference between them are discussed in full detail in Model Structure and Modules of the Language Reference.
AIMMS library
For your convenience, AIMMS always includes a single, read-only library
module called Predeclared Identifiers (displayed in
Fig. 10), containing all the identifiers that are
predeclared by AIMMS, categorized by function.
Non-structuring nodes
All remaining nodes in the tree refer to actual declarations of identifiers, procedures and functions. These nodes form the actual contents of your modeling application, as they represent the set, parameter and variable declarations that are necessary to represent your application, together with the actions that you want to perform on these identifiers.
Identifier nodes
The most frequent type of node in the model tree is the identifier
declaration node. All identifiers in your model are visible in the model
explorer as leaf nodes in the declaration sections. Identifier
declarations are not allowed outside of declaration sections. AIMMS
supports several identifier types which are all represented by a
different icon. The most common identifier types (i.e. sets, parameters,
variables and constraints) can be added to the model tree by pressing
one of the buttons  (the last button opens a selection list
of all available identifier types). Identifier declarations are
explained in full detail in Identifier Declarations.
(the last button opens a selection list
of all available identifier types). Identifier declarations are
explained in full detail in Identifier Declarations.
Independent order
Identifiers can be used independently of the order in which they have been declared in the model tree. As a matter of fact, you may use an identifier in an expression near the beginning of the tree, while its declaration is placed further down the tree. This order independence makes it possible to store identifiers where you think they should be stored logically, which adds to the overall maintainability of your model. This is different from most other systems where the order of identifiers is dictated by the order in which they are used inside the model description.
Procedure and function nodes
Another frequently occurring node type is the declaration of a procedure
or a function. Such a procedure or function node contains the data
retrieval statements, computations, and algorithms that make up the
procedural execution of your modeling application. Procedures and
functions are represented by folder icons,  and
and  ,
which open when the procedure or function node is expanded. They can be
inserted in the model tree in the root node or in any book section. The
fine details of procedure and function declarations are explained in
Procedures and Functions.
,
which open when the procedure or function node is expanded. They can be
inserted in the model tree in the root node or in any book section. The
fine details of procedure and function declarations are explained in
Procedures and Functions.
Procedure and function subnodes
Procedures and functions may contain their own declaration sections for their arguments and local identifiers. In addition, a procedure or function can be subdivided into logical components which are inserted into the body of that procedure or function, and are stored as execution subnodes. Such execution subnodes allow you to follow a top-down approach in implementing an algorithm without the need to introduce separate procedures to perform every single step. The complete list of permitted subnodes is discussed in Procedures and Functions.
Attributes
For every node in the model tree you can specify additional information in the form of attributes. AIMMS lets you view and change the values of these attributes in an attribute form that can be opened for every node in the tree. An example of an attribute form of an identifier node is shown in Fig. 11.
Such an attribute form shows all the attributes that are possible for a particular node type. For instance, the attribute form of a parameter declaration will show its domain of definition and value range, while the form for a procedure will show the argument list and procedure body. In the attribute form you can enter values that are relevant for your model.
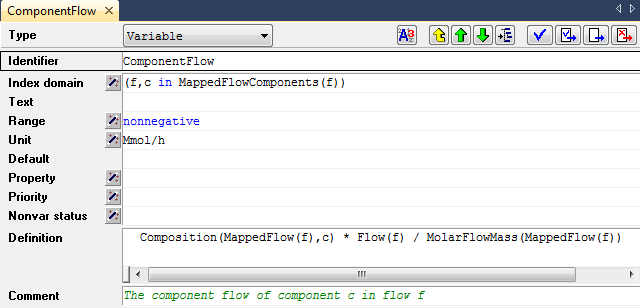
Fig. 11 Example of an attribute form
Wizards
For most attributes in an attribute form AIMMS provides wizards which
help you complete the attributes with which you are not familiar.
Attribute wizards can be invoked by pressing the small buttons
 in front of the attribute fields as shown in
Fig. 11. The wizard dialog boxes may range
from presenting a fixed selection of properties, to presenting a
relevant subselection of data from your model which can be used to
complete the attribute.
in front of the attribute fields as shown in
Fig. 11. The wizard dialog boxes may range
from presenting a fixed selection of properties, to presenting a
relevant subselection of data from your model which can be used to
complete the attribute.
Reduce syntax knowledge
By providing attribute forms and their associated wizards for the declaration of all identifiers, the amount of syntax knowledge required to set up the model source is drastically reduced. The attribute window of each identifier provides you with a complete overview of all the available attributes for that particular type of identifier. The wizards, in most cases, guide you through one or more dialog boxes in which you can choose from a number of possible options. After selecting the options relevant to your model, AIMMS will subsequently enter these in the attribute form using the correct syntax.
Local compilation
Once your complete model has been compiled successfully, attribute changes to a single identifier usually require only the recompilation of that identifier before the model can be executed again. This local compilation feature of AIMMS allows you to quickly observe the effect of particular attribute changes.
…versus global compilation
However, when you make changes to some attributes that have global implications for the rest of your model, local compilation will no longer be sufficient. In such a case, AIMMS will automatically recompile the entire model before you can execute it again. Global recompilation is necessary, for instance, when you change the dimension of a particular identifier. In this case global re- compilation is required, since the identifier could be referenced elsewhere in your model.
Attributes of structuring nodes
The attributes of structuring nodes allow you to specify documentation regarding the contents of that node. You can also provide directives to AIMMS to store a section node and all its offshoots in a separate file which is to be included when the model is compiled. Storing parts of your model in separate model files is discussed in more detail in Creating and managing models.