Observing identifier cardinalities
Observing identifier cardinalities
Another possible cause of performance problems is when one or more multi- dimensional identifiers in your model have missing or incorrectly specified domain conditions. As a result, AIMMS could store far too much data for such identifiers. In addition, computations with these identifiers may consume a disproportional amount of time.
Locating cardinality problems
To help you locate identifiers with missing or incorrectly specified domain conditions, AIMMS offers the Identifier Cardinalities dialog box illustrated in Fig. 47. You can invoke it through the Tools-Diagnostic Tools-Identifier Cardinalities menu.
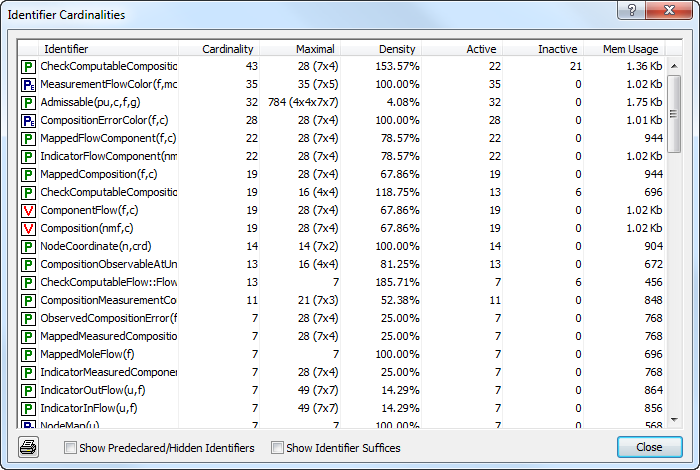
Fig. 47 The Identifier Cardinalities dialog box
Available information
The Identifier Cardinalities dialog box displays the following information for each identifier in your model:
the cardinality of the identifier, i.e. the total number of non-default values currently stored,
the maximal cardinality, i.e. the cardinality if all values would assume a non-default value,
the density, i.e. the cardinality as a percentage of the maximal cardinality,
the number of active values, i.e. of elements that lie within the domain of the identifier,
the number of inactive values, i.e. of elements that lie outside of the domain of the identifier, and
the memory usage of the identifier, i.e. the amount of memory needed to store the identifier data.
The list of identifier cardinalities can be sorted with respect to any of these values.
Locating dense data storage
You can locate potential dense data storage problems by sorting all identifiers by their cardinality. Identifiers with a very high cardinality and a high density can indicate a missing or incorrectly specified domain condition. In most real-world applications, the higher-dimensional identifiers usually have relatively few tuples, as only a very small number of combinations have a meaningful interpretation.
Resolving dense storage
If your model contains one or more identifiers that appear to demonstrate dense data storage, it is often possible to symbolicly describe the appropriate domain of allowed tuple combinations. Adding such a condition can be helpful to increase the performance of your model by reducing both the memory usage and execution times.
Locating inactive data
Another type of problem that you can locate with the Identifier Cardinalities dialog box, is the occurrence of inactive data in your model. Inactive data can be caused by
the removal of elements in one or more domain sets, or
data modifications in the identifier(s) involved in the domain restriction of the identifier.
Problems with inactive data
In principle, inactive data does not directly influence the behavior of your model, as the AIMMS execution engine itself will never consider inactive data. Inactive data, however, can cause unexpected problems in some specific situations.
One of the areas where you have to be aware about inactive data is in the AIMMS API (see also The AIMMS Programming Interface of the Language Reference), where you have to decide whether or not you want the AIMMS API to pass inactive data to an external application or DLL.
Also, when inactive data becomes active again, the previous values are retained, which may or may not be what you intended.
As a result, the occurrence of inactive data in the Identifier Cardinalities dialog box may make you rethink its consequences, and may cause you to add statements to your model to remove the inactive data explicitly (see also Data Control of the Language Reference).